In Chapter 8 we introduced the basic architecture and most commonly used parts of the IO library. In this section we’ll look at three of the more specialized features that the IO library supports: format control, unformatted IO, and random access.
Exercises Section 17.4.2
Exercise 17.31: What would happen if we defined
bandeinside thedoloop of the game-playing program from this section?Exercise 17.32: What would happen if we defined
respinside the loop?Exercise 17.33: Write a version of the word transformation program from § 11.3.6 (p. 440) that allows multiple transformations for a given word and randomly selects which transformation to apply.
In addition to its condition state (§ 8.1.2, p. 312), each iostream object also maintains a format state that controls the details of how IO is formatted. The format state controls aspects of formatting such as the notational base for integral values, the precision of floating-point values, the width of an output element, and so on.
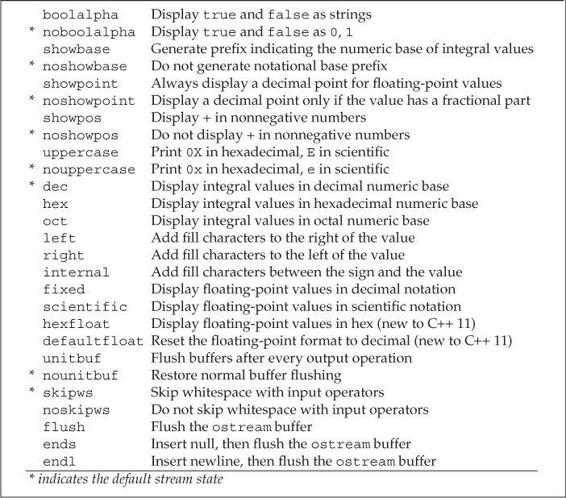
The library defines a set of manipulators (§ 1.2, p. 7), listed in Tables 17.17 (p. 757) and 17.18 (p. 760), that modify the format state of a stream. A manipulator is a function or object that affects the state of a stream and can be used as an operand to an input or output operator. Like the input and output operators, a manipulator returns the stream object to which it is applied, so we can combine manipulators and data in a single statement.
Our programs have already used one manipulator, endl, which we “write” to an output stream as if it were a value. But endl isn’t an ordinary value; instead, it performs an operation: It writes a newline and flushes the buffer.
Manipulators are used for two broad categories of output control: controlling the presentation of numeric values and controlling the amount and placement of padding. Most of the manipulators that change the format state provide set/unset pairs; one manipulator sets the format state to a new value and the other unsets it, restoring the normal default formatting.
Manipulators that change the format state of the stream usually leave the format state changed for all subsequent IO.
The fact that a manipulator makes a persistent change to the format state can be useful when we have a set of IO operations that want to use the same formatting. Indeed, some programs take advantage of this aspect of manipulators to reset the behavior of one or more formatting rules for all its input or output. In such cases, the fact that a manipulator changes the stream is a desirable property.
However, many programs (and, more importantly, programmers) expect the state of the stream to match the normal library defaults. In these cases, leaving the state of the stream in a nonstandard state can lead to errors. As a result, it is usually best to undo whatever state changes are made as soon as those changes are no longer needed.
One example of a manipulator that changes the formatting state of its object is the boolalpha manipulator. By default, bool values print as 1 or 0. A true value is written as the integer 1 and a false value as 0. We can override this formatting by applying the boolalpha manipulator to the stream:
cout << "default bool values: " << true << " " << false
<< "\nalpha bool values: " << boolalpha
<< true << " " << false << endl;
When executed, this program generates the following:
default bool values: 1 0
alpha bool values: true false
Once we “write” boolalpha on cout, we’ve changed how cout will print bool values from this point on. Subsequent operations that print bools will print them as either true or false.
To undo the format state change to cout, we apply noboolalpha:
bool bool_val = get_status();
cout << boolalpha // sets the internal state of cout
<< bool_val
<< noboolalpha; // resets the internal state to default formatting
Here we change the format of bool values only to print the value of bool_val. Once that value is printed, we immediately reset the stream back to its initial state.
By default, integral values are written and read in decimal notation. We can change the notational base to octal or hexadecimal or back to decimal by using the manipulators hex, oct, and dec:
cout << "default: " << 20 << " " << 1024 << endl;
cout << "octal: " << oct << 20 << " " << 1024 << endl;
cout << "hex: " << hex << 20 << " " << 1024 << endl;
cout << "decimal: " << dec << 20 << " " << 1024 << endl;
When compiled and executed, this program generates the following output:
default: 20 1024
octal: 24 2000
hex: 14 400
decimal: 20 1024
Notice that like boolalpha, these manipulators change the format state. They affect the immediately following output and all subsequent integral output until the format is reset by invoking another manipulator.
The
hex, oct, anddecmanipulators affect only integral operands; the representation of floating-point values is unaffected.
By default, when we print numbers, there is no visual cue as to what notational base was used. Is 20, for example, really 20, or an octal representation of 16? When we print numbers in decimal mode, the number is printed as we expect. If we need to print octal or hexadecimal values, it is likely that we should also use the showbase manipulator. The showbase manipulator causes the output stream to use the same conventions as used for specifying the base of an integral constant:
• A leading 0x indicates hexadecimal.
• A leading 0 indicates octal.
• The absence of either indicates decimal.
Here we’ve revised the previous program to use showbase:
cout << showbase; // show the base when printing integral values
cout << "default: " << 20 << " " << 1024 << endl;
cout << "in octal: " << oct << 20 << " " << 1024 << endl;
cout << "in hex: " << hex << 20 << " " << 1024 << endl;
cout << "in decimal: " << dec << 20 << " " << 1024 << endl;
cout << noshowbase; // reset the state of the stream
The revised output makes it clear what the underlying value really is:
default: 20 1024
in octal: 024 02000
in hex: 0x14 0x400
in decimal: 20 1024
The noshowbase manipulator resets cout so that it no longer displays the notational base of integral values.
By default, hexadecimal values are printed in lowercase with a lowercase x. We can display the X and the hex digits a–f as uppercase by applying the uppercase manipulator:
cout << uppercase << showbase << hex
<< "printed in hexadecimal: " << 20 << " " << 1024
<< nouppercase << noshowbase << dec << endl;
This statement generates the following output:
printed in hexadecimal: 0X14 0X400
We apply the nouppercase, noshowbase, and dec manipulators to return the stream to its original state.
We can control three aspects of floating-point output:
• How many digits of precision are printed
• Whether the number is printed in hexadecimal, fixed decimal, or scientific notation
• Whether a decimal point is printed for floating-point values that are whole numbers
By default, floating-point values are printed using six digits of precision; the decimal point is omitted if the value has no fractional part; and they are printed in either fixed decimal or scientific notation depending on the value of the number. The library chooses a format that enhances readability of the number. Very large and very small values are printed using scientific notation. Other values are printed in fixed decimal.
By default, precision controls the total number of digits that are printed. When printed, floating-point values are rounded, not truncated, to the current precision. Thus, if the current precision is four, then 3.14159 becomes 3.142; if the precision is three, then it is printed as 3.14.
We can change the precision by calling the precision member of an IO object or by using the setprecision manipulator. The precision member is overloaded (§ 6.4, p. 230). One version takes an int value and sets the precision to that new value. It returns the previous precision value. The other version takes no arguments and returns the current precision value. The setprecision manipulator takes an argument, which it uses to set the precision.
The
setprecisionmanipulators and other manipulators that take arguments are defined in theiomanipheader.
The following program illustrates the different ways we can control the precision used to print floating-point values:
// cout.precision reports the current precision value
cout << "Precision: " << cout.precision()
<< ", Value: " << sqrt(2.0) << endl;
// cout.precision(12) asks that 12 digits of precision be printed
cout.precision(12);
cout << "Precision: " << cout.precision()
<< ", Value: " << sqrt(2.0) << endl;
// alternative way to set precision using the setprecision manipulator
cout << setprecision(3);
cout << "Precision: " << cout.precision()
<< ", Value: " << sqrt(2.0) << endl;
When compiled and executed, the program generates the following output:
Precision: 6, Value: 1.41421
Precision: 12, Value: 1.41421356237
Precision: 3, Value: 1.41
Table 17.17. Manipulators Defined in iostream
This program calls the library sqrt function, which is found in the cmath header. The sqrt function is overloaded and can be called on either a float, double, or long double argument. It returns the square root of its argument.
Unless you need to control the presentation of a floating-point number (e.g., to print data in columns or to print data that represents money or a percentage), it is usually best to let the library choose the notation.
We can force a stream to use scientific, fixed, or hexadecimal notation by using the appropriate manipulator. The scientific manipulator changes the stream to use scientific notation. The fixed manipulator changes the stream to use fixed decimal.
Under the new library, we can also force floating-point values to use hexadecimal format by using hexfloat. The new library provides another manipulator, named defaultfloat. This manipulator returns the stream to its default state in which it chooses a notation based on the value being printed.
These manipulators also change the default meaning of the precision for the stream. After executing scientific, fixed, or hexfloat, the precision value controls the number of digits after the decimal point. By default, precision specifies the total number of digits—both before and after the decimal point. Using fixed or scientific lets us print numbers lined up in columns, with the decimal point in a fixed position relative to the fractional part being printed:
cout << "default format: " << 100 * sqrt(2.0) << '\n'
<< "scientific: " << scientific << 100 * sqrt(2.0) << '\n'
<< "fixed decimal: " << fixed << 100 * sqrt(2.0) << '\n'
<< "hexadecimal: " << hexfloat << 100 * sqrt(2.0) << '\n'
<< "use defaults: " << defaultfloat << 100 * sqrt(2.0)
<< "\n\n";
produces the following output:
default format: 141.421
scientific: 1.414214e+002
fixed decimal: 141.421356
hexadecimal: 0x1.1ad7bcp+7
use defaults: 141.421
By default, the hexadecimal digits and the e used in scientific notation are printed in lowercase. We can use the uppercase manipulator to show those values in uppercase.
By default, when the fractional part of a floating-point value is 0, the decimal point is not displayed. The showpoint manipulator forces the decimal point to be printed:
cout << 10.0 << endl; // prints 10
cout << showpoint << 10.0 // prints 10.0000
<< noshowpoint << endl; // revert to default format for the decimal point
The noshowpoint manipulator reinstates the default behavior. The next output expression will have the default behavior, which is to suppress the decimal point if the floating-point value has a 0 fractional part.
When we print data in columns, we often need fairly fine control over how the data are formatted. The library provides several manipulators to help us accomplish the control we might need:
•
setwto specify the minimum space for the next numeric or string value.
•
leftto left-justify the output.
•
rightto right-justify the output. Output is right-justified by default.
•
internalcontrols placement of the sign on negative values.internalleft-justifies the sign and right-justifies the value, padding any intervening space with blanks.
•
setfilllets us specify an alternative character to use to pad the output. By default, the value is a space.
setw, likeendl, does not change the internal state of the output stream. It determines the size of only the next output.
The following program illustrates these manipulators:
int i = -16;
double d = 3.14159;
// pad the first column to use a minimum of 12 positions in the output
cout << "i: " << setw(12) << i << "next col" << '\n'
<< "d: " << setw(12) << d << "next col" << '\n';
// pad the first column and left-justify all columns
cout << left
<< "i: " << setw(12) << i << "next col" << '\n'
<< "d: " << setw(12) << d << "next col" << '\n'
<< right; // restore normal justification
// pad the first column and right-justify all columns
cout << right
<< "i: " << setw(12) << i << "next col" << '\n'
<< "d: " << setw(12) << d << "next col" << '\n';
// pad the first column but put the padding internal to the field
cout << internal
<< "i: " << setw(12) << i << "next col" << '\n'
<< "d: " << setw(12) << d << "next col" << '\n';
// pad the first column, using # as the pad character
cout << setfill('#')
<< "i: " << setw(12) << i << "next col" << '\n'
<< "d: " << setw(12) << d << "next col" << '\n'
<< setfill(' '); // restore the normal pad character
When executed, this program generates
i: -16next col
d: 3.14159next col
i: -16 next col
d: 3.14159 next col
i: -16next col
d: 3.14159next col
i: - 16next col
d: 3.14159next col
i: -#########16next col
d: #####3.14159next col
Table 17.18. Manipulators Defined in iomanip

By default, the input operators ignore whitespace (blank, tab, newline, formfeed, and carriage return). The following loop
char ch;
while (cin >> ch)
cout << ch;
given the input sequence
a b c
d
executes four times to read the characters a through d, skipping the intervening blanks, possible tabs, and newline characters. The output from this program is
abcd
The noskipws manipulator causes the input operator to read, rather than skip, whitespace. To return to the default behavior, we apply the skipws manipulator:
cin >> noskipws; // set cin so that it reads whitespace
while (cin >> ch)
cout << ch;
cin >> skipws; // reset cin to the default state so that it discards whitespace
Given the same input as before, this loop makes seven iterations, reading whitespace as well as the characters in the input. This loop generates
a b c
d
Exercises Section 17.5.1
Exercise 17.34: Write a program that illustrates the use of each manipulator in Tables 17.17 (p. 757) and 17.18.
Exercise 17.35: Write a version of the program from page 758, that printed the square root of 2 but this time print hexadecimal digits in uppercase.
Exercise 17.36: Modify the program from the previous exercise to print the various floating-point values so that they line up in a column.
So far, our programs have used only formatted IO operations. The input and output operators (<< and >>) format the data they read or write according to the type being handled. The input operators ignore whitespace; the output operators apply padding, precision, and so on.
The library also provides a set of low-level operations that support unformatted IO. These operations let us deal with a stream as a sequence of uninterpreted bytes.
Several of the unformatted operations deal with a stream one byte at a time. These operations, which are described in Table 17.19, read rather than ignore whitespace. For example, we can use the unformatted IO operations get and put to read and write the characters one at a time:
char ch;
while (cin.get(ch))
cout.put(ch);
This program preserves the whitespace in the input. Its output is identical to the input. It executes the same way as the previous program that used noskipws.
Table 17.19. Single-Byte Low-Level IO Operations

Sometimes we need to read a character in order to know that we aren’t ready for it. In such cases, we’d like to put the character back onto the stream. The library gives us three ways to do so, each of which has subtle differences from the others:
•
peekreturns a copy of the next character on the input stream but does not change the stream. The value returned bypeekstays on the stream.
•
ungetbacks up the input stream so that whatever value was last returned is still on the stream. We can callungeteven if we do not know what value was last taken from the stream.
•
putbackis a more specialized version ofunget:It returns the last value read from the stream but takes an argument that must be the same as the one that was last read.
In general, we are guaranteed to be able to put back at most one value before the next read. That is, we are not guaranteed to be able to call putback or unget successively without an intervening read operation.
int Return Values from Input OperationsThe peek function and the version of get that takes no argument return a character from the input stream as an int. This fact can be surprising; it might seem more natural to have these functions return a char.
The reason that these functions return an int is to allow them to return an end-of-file marker. A given character set is allowed to use every value in the char range to represent an actual character. Thus, there is no extra value in that range to use to represent end-of-file.
The functions that return int convert the character they return to unsigned char and then promote that value to int. As a result, even if the character set has characters that map to negative values, the int returned from these operations will be a positive value (§ 2.1.2, p. 35). The library uses a negative value to represent end-of-file, which is thus guaranteed to be distinct from any legitimate character value. Rather than requiring us to know the actual value returned, the iostream header defines a const named EOF that we can use to test if the value returned from get is end-of-file. It is essential that we use an int to hold the return from these functions:
int ch; // use an int, not a char to hold the return from get()
// loop to read and write all the data in the input
while ((ch = cin.get()) != EOF)
cout.put(ch);
This program operates identically to the one on page 761, the only difference being the version of get that is used to read the input.
Some unformatted IO operations deal with chunks of data at a time. These operations can be important if speed is an issue, but like other low-level operations, they are error-prone. In particular, these operations require us to allocate and manage the character arrays (§ 12.2, p. 476) used to store and retrieve data. The multi-byte operations are listed in Table 17.20.
Table 17.20. Multi-Byte Low-Level IO Operations

The get and getline functions take the same parameters, and their actions are similar but not identical. In each case, sink is a char array into which the data are placed. The functions read until one of the following conditions occurs:
•
size - 1characters are read
• End-of-file is encountered
• The delimiter character is encountered
The difference between these functions is the treatment of the delimiter: get leaves the delimiter as the next character of the istream, whereas getline reads and discards the delimiter. In either case, the delimiter is not stored in sink.
Several of the read operations read an unknown number of bytes from the input. We can call gcount to determine how many characters the last unformatted input operation read. It is essential to call gcount before any intervening unformatted input operation. In particular, the single-character operations that put characters back on the stream are also unformatted input operations. If peek, unget, or putback are called before calling gcount, then the return value will be 0.
The various stream types generally support random access to the data in their associated stream. We can reposition the stream so that it skips around, reading first the last line, then the first, and so on. The library provides a pair of functions to seek to a given location and to tell the current location in the associated stream.
Random IO is an inherently system-dependent. To understand how to use these features, you must consult your system’s documentation.
Although these seek and tell functions are defined for all the stream types, whether they do anything useful depends on the device to which the stream is bound. On most systems, the streams bound to cin, cout, cerr, and clog do not support random access—after all, what would it mean to jump back ten places when we’re writing directly to cout? We can call the seek and tell functions, but these functions will fail at run time, leaving the stream in an invalid state.
In general, we advocate using the higher-level abstractions provided by the library. The IO operations that return
intare a good example of why.It is a common programming error to assign the return, from
getorpeekto acharrather than anint. Doing so is an error, but an error the compiler will not detect. Instead, what happens depends on the machine and on the input data. For example, on a machine in whichchars are implemented asunsigned chars, this loop will run forever:char ch; // using a char here invites disaster!
// the return from cin.get is converted to char and then compared to an int
while ((ch = cin.get()) != EOF)
cout.put(ch);The problem is that when
getreturnsEOF, that value will be converted to anunsigned charvalue. That converted value is no longer equal to theintvalue ofEOF, and the loop will continue forever. Such errors are likely to be caught in testing.On machines for which
chars are implemented assigned chars, we can’t say with confidence what the behavior of the loop might be. What happens when an out-of-bounds value is assigned to asignedvalue is up to the compiler. On many machines, this loop will appear to work, unless a character in the input matches the EOF value. Although such characters are unlikely in ordinary data, presumably low-level IO is necessary only when we read binary values that do not map directly to ordinary characters and numeric values. For example, on our machine, if the input contains a character whose value is'\377', then the loop terminates prematurely.'\377'is the value on our machine to which −1 converts when used as asigned char. If the input has this value, then it will be treated as the (premature) end-of-file indicator.Such bugs do not happen when we read and write typed values. If you can use the more type-safe, higher-level operations supported by the library, do so.
Exercises Section 17.5.2
Exercise 17.37: Use the unformatted version of
getlineto read a file a line at a time. Test your program by giving it a file that contains empty lines as well as lines that are longer than the character array that you pass togetline.Exercise 17.38: Extend your program from the previous exercise to print each word you read onto its own line.
Because the
istreamandostreamtypes usually do not support random access, the remainder of this section should be considered as applicable to only thefstreamandsstreamtypes.
To support random access, the IO types maintain a marker that determines where the next read or write will happen. They also provide two functions: One repositions the marker by seeking to a given position; the second tells us the current position of the marker. The library actually defines two pairs of seek and tell functions, which are described in Table 17.21. One pair is used by input streams, the other by output streams. The input and output versions are distinguished by a suffix that is either a g or a p. The g versions indicate that we are “getting” (reading) data, and the p functions indicate that we are “putting” (writing) data.
Table 17.21. Seek and Tell Functions

Logically enough, we can use only the g versions on an istream and on the types ifstream and istringstream that inherit from istream (§ 8.1, p. 311). We can use only the p versions on an ostream and on the types that inherit from it, ofstream and ostringstream. An iostream, fstream, or stringstream can both read and write the associated stream; we can use either the g or p versions on objects of these types.
The fact that the library distinguishes between the “putting” and “getting” versions of the seek and tell functions can be misleading. Even though the library makes this distinction, it maintains only a single marker in a stream—there is not a distinct read marker and write marker.
When we’re dealing with an input-only or output-only stream, the distinction isn’t even apparent. We can use only the g or only the p versions on such streams. If we attempt to call tellp on an ifstream, the compiler will complain. Similarly, it will not let us call seekg on an ostringstream.
The fstream and stringstream types can read and write the same stream. In these types there is a single buffer that holds data to be read and written and a single marker denoting the current position in the buffer. The library maps both the g and p positions to this single marker.
Because there is only a single marker, we must do a
seekto reposition the marker whenever we switch between reading and writing.
There are two versions of the seek functions: One moves to an “absolute” address within the file; the other moves to a byte offset from a given position:
// set the marker to a fixed position
seekg(new_position); // set the read marker to the given pos_type location
seekp(new_position); // set the write marker to the given pos_type location
// offset some distance ahead of or behind the given starting point
seekg(offset, from); // set the read marker offset distance from from
seekp(offset, from); // offset has type off_type
The possible values for from are listed in Table 17.21 (on the previous page).
The arguments, new_position and offset, have machine-dependent types named pos_type and off_type, respectively. These types are defined in both istream and ostream. pos_type represents a file position and off_type represents an offset from that position. A value of type off_type can be positive or negative; we can seek forward or backward in the file.
The tellg or tellp functions return a pos_type value denoting the current position of the stream. The tell functions are usually used to remember a location so that we can subsequently seek back to it:
// remember the current write position in mark
ostringstream writeStr; // output stringstream
ostringstream::pos_type mark = writeStr.tellp();
// ...
if (cancelEntry)
// return to the remembered position
writeStr.seekp(mark);
Let’s look at a programming example. Assume we are given a file to read. We are to write a newline at the end of the file that contains the relative position at which each line begins. For example, given the following file,
abcd
efg
hi
j
the program should produce the following modified file:
Note that our program need not write the offset for the first line—it always occurs at position 0. Also note that the offset counts must include the invisible newline character that ends each line. Finally, note that the last number in the output is the offset for the line on which our output begins. By including this offset in our output, we can distinguish our output from the file’s original contents. We can read the last number in the resulting file and seek to the corresponding offset to get to the beginning of our output.
Our program will read the file a line at a time. For each line, we’ll increment a counter, adding the size of the line we just read. That counter is the offset at which the next line starts:
int main()
{
// open for input and output and preposition file pointers to end-of-file
// file mode argument see § 8.4 (p. 319)
fstream inOut("copyOut",
fstream::ate | fstream::in | fstream::out);
if (!inOut) {
cerr << "Unable to open file!" << endl;
return EXIT_FAILURE; // EXIT_FAILURE see § 6.3.2 (p. 227)
}
// inOut is opened in ate mode, so it starts out positioned at the end
auto end_mark = inOut.tellg();// remember original end-of-file position
inOut.seekg(0, fstream::beg); // reposition to the start of the file
size_t cnt = 0; // accumulator for the byte count
string line; // hold each line of input
// while we haven't hit an error and are still reading the original data
while (inOut && inOut.tellg() != end_mark
&& getline(inOut, line)) { // and can get another line of input
cnt += line.size() + 1; // add 1 to account for the newline
auto mark = inOut.tellg(); // remember the read position
inOut.seekp(0, fstream::end); // set the write marker to the end
inOut << cnt; // write the accumulated length
// print a separator if this is not the last line
if (mark != end_mark) inOut << " ";
inOut.seekg(mark); // restore the read position
}
inOut.seekp(0, fstream::end); // seek to the end
inOut << "\n"; // write a newline at end-of-file
return 0;
}
Our program opens its fstream using the in, out, and ate modes (§ 8.4, p. 319). The first two modes indicate that we intend to read and write the same file. Specifying ate positions the read and write markers at the end of the file. As usual, we check that the open succeeded, and exit if it did not (§ 6.3.2, p. 227).
Because our program writes to its input file, we can’t use end-of-file to signal when it’s time to stop reading. Instead, our loop must end when it reaches the point at which the original input ended. As a result, we must first remember the original end-of-file position. Because we opened the file in ate mode, inOut is already positioned at the end. We store the current (i.e., the original end) position in end_mark. Having remembered the end position, we reposition the read marker at the beginning of the file by seeking to the position 0 bytes from the beginning of the file.
The while loop has a three-part condition: We first check that the stream is valid; if so, we check whether we’ve exhausted our original input by comparing the current read position (returned by tellg) with the position we remembered in end_mark. Finally, assuming that both tests succeeded, we call getline to read the next line of input. If getline succeeds, we perform the body of the loop.
The loop body starts by remembering the current position in mark. We save that position in order to return to it after writing the next relative offset. The call to seekp repositions the write marker to the end of the file. We write the counter value and then seekg back to the position we remembered in mark. Having restored the marker, we’re ready to repeat the condition in the while.
Each iteration of the loop writes the offset of the next line. Therefore, the last iteration of the loop takes care of writing the offset of the last line. However, we still need to write a newline at the end of the file. As with the other writes, we call seekp to position the file at the end before writing the newline.
Exercises Section 17.5.3
Exercise 17.39: Write your own version of the
seekprogram presented in this section.
 Warning
Warning Note
Note Best Practices
Best Practices